Giới thiệu
Giới thiệu về mô hình LLM phân tán trên Orange Pi
Hiện nay, trí tuệ nhân tạo (AI) đã có thể tóm tắt bài báo, viết truyện làm thơ và tham gia tương tác tự nhiên với con người thông qua các cuộc trò chuyện dài. Đứng đằng sau thành công này một phần là Large Language Models. Large Language Models (hay LLM) để chỉ các mô hình xác suất có khả năng hiểu và sinh ngôn ngữ tự nhiên dựa trên kiến thức được thu thập từ các tập dữ liệu cực lớn. LLM là một trong những ứng dụng thành công nhất của các mô hình transformer.
Một mô hình ngôn ngữ có thể có độ phức tạp khác nhau, từ các mô hình n-gram đơn giản đến các mô hình mạng mô phỏng hệ thần kinh của con người vô cùng phức tạp. Tuy nhiên, thuật ngữ Large Language Model thường dùng để chỉ các mô hình sử dụng kỹ thuật học sâu và có số lượng tham số lớn, có thể từ hàng tỷ đến hàng nghìn tỷ. Những mô hình này có thể phát hiện các quy luật phức tạp trong ngôn ngữ và tạo ra các văn bản y hệt con người. Các con số phía sau mỗi mô hình ví dụ Gemma-1B hay Qwen-3B là chỉ số lượng tham số mà mô hình được huấn luyện, trong đó B là Billion tức là 1 tỷ.
Việc triển khai các mô hình LLM này trước giờ đều sử dụng các máy chủ GPU hoặc các card màn hình với công suất lớn, giá trị cao và tiêu thụ rất nhiều năng lượng để thực hiện. Như bài báo ở trên, ChatGPU tiêu thụ đến nửa triệu kWh điện mỗi ngày, hãy thử tưởng tượng bao nhiêu than được đốt ra để tạo ra lượng điện khổng lồ ấy, và cả khí thải ra môi trường nữa. Trong khi đó các mạch máy tính đơn SBC Orange Pi có NPU có thể xử lý được các mô hình ngôn ngữ lớn LLM lại tiêu thụ cực ít năng lượng, tối da chỉ từ 10-15W mỗi bo mạch. Chính vì vậy, Orange Pi Việt Nam đã công bố ra mô hình LLM phân tán trên Orange Pi PI để giảm thiểu việc tiêu thụ năng lượng và bảo vệ môi trường.
Đặc điểm của việc xử lý mô hình ngôn ngữ lớn LLM trên các máy tính đơn bo mạch Orange Pi có NPU là nó chỉ xử lý được một phiên làm việc tại một thời điểm. Chính vì thế nó không thể sử dụng làm máy chủ để phục vụ chatbot cho nhiều người dùng, nhất là việc áp dụng RAG (Retrieval-Augmented Generation). Trong khi mà các chatbot cần truy cập và kho dữ liệu (knowledge library), lấy dữ liệu trong ngữ cảnh ra để trả lời cho người dùng, bằng cách sử dụng LLM làm trung gian tạo ra câu trả lời giống con người hơn, hay còn gọi là AI tạo sinh (Generative AI), thì mô hình LLM phân tán như trên đã giải quyết được các vấn đề mà lại đáp ứng được mọi yêu cầu như một máy chủ GPU.
Mô hình LLM phân tán trên Orange Pi sẽ sử dụng các Orange Pi như các đơn vị tạo sinh ngôn ngữ, còn lại việc phân tách dữ liệu từ kho tài liệu (embedding và reranking) sẽ sử dụng máy chủ X86 thông thường, khi quản trị viên đưa dữ liệu vào và user nhập câu hỏi, máy chủ X86 sẽ sử lý công việc tạo token và chuyển câu hỏi thành token, sau đó trả về thông tin theo đúng ngữ cảnh. Orange Pi lúc đó sẽ dùng thông tin theo đúng ngữ cảnh, chuyển thành ngôn ngữ tạo sinh, và trả lời user. Trong trường hợp câu hỏi khong nằm trong ngữ cảnh hoặc nội dung được trả lời, Orange PI cũng se phản hồi câu trả lời từ chối ngay lập tức. Với việc sử dụng NPU trên chip RK3588 để xử lý LLM, tốc độ phản hồi ngôn ngữ sẽ nhanh hơn rất nhiều, kể cả so với việc sử dụng GPU khi có nhiều người dùng cùng lúc.
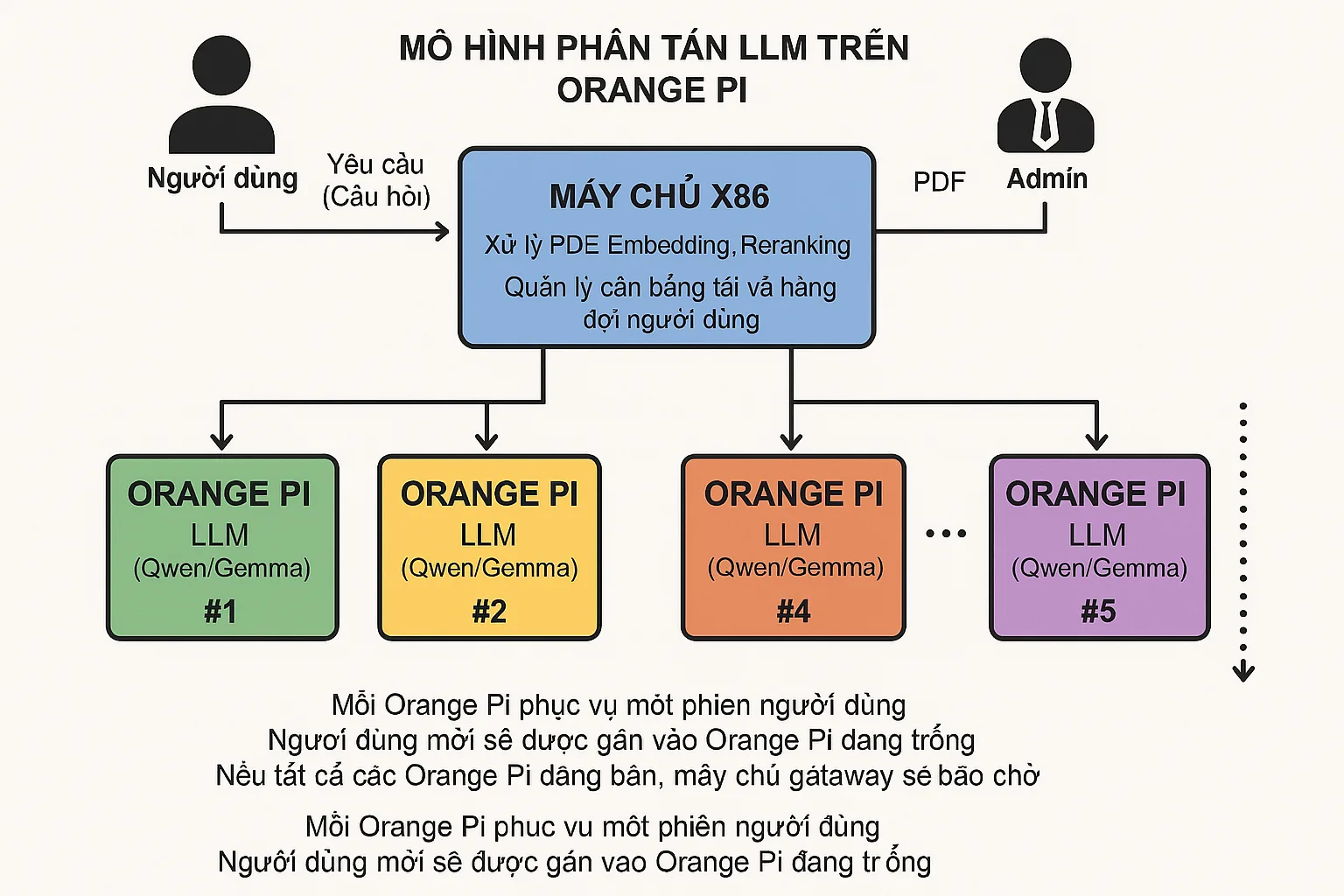
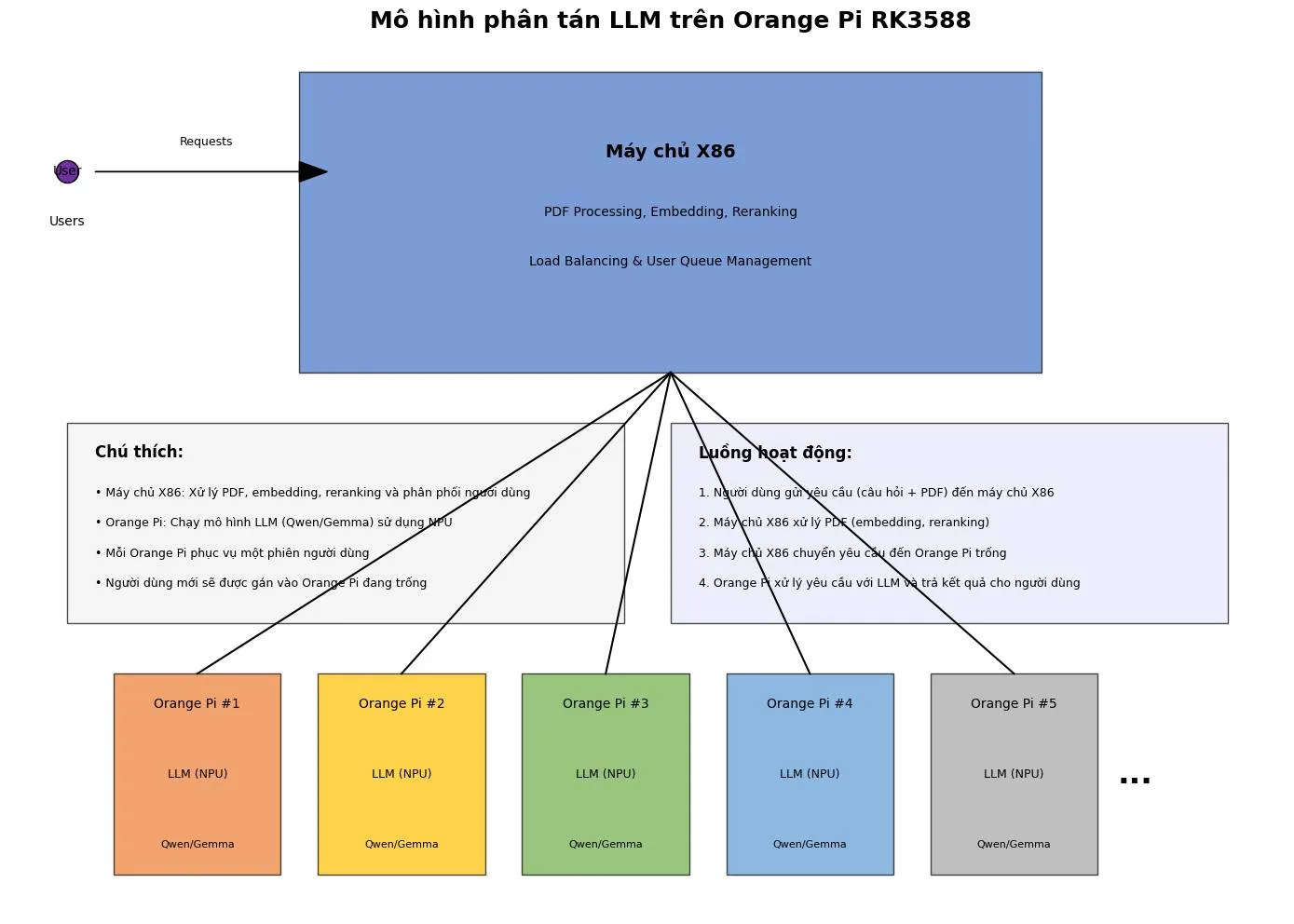
Mô hình phân tán LLM trên Orange Pi RK3588
Hình ảnh minh họa kiến trúc hệ thống phân tán LLM sử dụng các thiết bị Orange Pi, bao gồm:
- Máy chủ X86 (hình chữ nhật màu xanh dương ở phía trên):
- Xử lý PDF, Embedding, Reranking
- Quản lý cân bằng tải và hàng đợi người dùng
- Các thiết bị Orange Pi (5 hình chữ nhật màu sắc khác nhau ở phía dưới):
- Mỗi Orange Pi chạy mô hình LLM (Qwen/Gemma) sử dụng NPU
- Được đánh số từ #1 đến #5 (và có thể mở rộng thêm)
- Kết nối:
- Người dùng gửi yêu cầu đến máy chủ X86
- Máy chủ phân phối các yêu cầu đến các Orange Pi trống
- Luồng hoạt động:
- Người dùng gửi yêu cầu (câu hỏi + PDF) đến máy chủ X86
- Máy chủ X86 xử lý PDF (embedding, reranking)
- Máy chủ X86 chuyển yêu cầu đến Orange Pi trống
- Orange Pi xử lý yêu cầu với LLM và trả kết quả cho người dùng
- Chú thích:
- Mỗi Orange Pi phục vụ một phiên người dùng
- Người dùng mới sẽ được gán vào Orange Pi đang trống
Lợi ích của mô hình phân tán LLM trên Orange Pi so với máy chủ GPU
1. Tiết kiệm chi phí đầu tư
- Chi phí máy chủ X86 Gateway + nhiều Orange Pi RK3588 thấp hơn đáng kể so với máy chủ GPU cao cấp
- Một Orange Pi RK3588 có giá khoảng 100-200 USD, trong khi GPU chuyên dụng cho AI có thể từ vài nghìn đến hàng chục nghìn USD
2. Tiết kiệm điện năng
- NPU trên Orange Pi tiêu thụ điện năng thấp hơn nhiều so với GPU mạnh
- Tổng công suất tiêu thụ của cả hệ thống (máy chủ X86 + nhiều Orange Pi) vẫn thấp hơn máy chủ GPU
3. Khả năng mở rộng linh hoạt (Scalability)
- Dễ dàng thêm Orange Pi mới khi cần tăng số lượng người dùng đồng thời
- Mở rộng theo chiều ngang (horizontal scaling) đơn giản hơn so với nâng cấp GPU
- Chi phí mở rộng tăng tuyến tính, không phải theo cấp số nhân như với GPU mạnh hơn
4. Tính sẵn sàng cao (High Availability)
- Nếu một Orange Pi gặp sự cố, chỉ ảnh hưởng đến một người dùng
- Hệ thống vẫn tiếp tục hoạt động với các Orange Pi còn lại
- Dễ dàng thay thế thiết bị lỗi mà không cần dừng toàn bộ hệ thống
5. Tối ưu cho nhiều người dùng đồng thời
- Mỗi người dùng có một thiết bị riêng xử lý yêu cầu của họ
- Không bị ảnh hưởng bởi việc chia sẻ tài nguyên GPU giữa nhiều người dùng
- Độ trễ ổn định hơn khi số lượng người dùng tăng
6. Dễ bảo trì và nâng cấp
- Có thể nâng cấp từng phần của hệ thống mà không ảnh hưởng đến toàn bộ
- Dễ dàng thay thế các Orange Pi cũ bằng phiên bản mới hơn, mạnh hơn
- Giảm thời gian ngừng hoạt động khi bảo trì
7. Phù hợp với mô hình LLM nhẹ
- Tận dụng tối ưu các mô hình LLM nhẹ như Qwen/Gemma được tối ưu cho NPU
- Hiệu quả cho các ứng dụng không yêu cầu mô hình cực lớn như GPT-4
8. Phân phối địa lý dễ dàng
- Có thể triển khai các cụm Orange Pi ở nhiều vị trí địa lý khác nhau
- Giảm độ trễ mạng cho người dùng ở các khu vực khác nhau
9. Khả năng chịu lỗi tốt hơn
- Thiết kế phân tán giúp hệ thống ít bị ảnh hưởng bởi lỗi phần cứng đơn lẻ
- Dễ dàng thiết lập dự phòng với chi phí thấp
10. Tùy biến theo nhu cầu
- Có thể cấu hình các Orange Pi khác nhau cho các nhiệm vụ khác nhau
- Linh hoạt trong việc triển khai các mô hình LLM khác nhau trên các thiết bị khác nhau
Mô hình này đặc biệt phù hợp cho các tổ chức vừa và nhỏ muốn triển khai giải pháp LLM tại chỗ (on-premise) với chi phí hợp lý và khả năng mở rộng theo thời gian. Nếu quý khách hàng có nhu cầu cần triển khai hệ thống tương tự, đừng chần chừ liên hệ ngay với Orange Pi Việt Nam tại link sau